
PostgreSQL
e' un potente DBMS relazionale Open Source noto per
la robustezza e la ricchezza di funzionalita'.
Questo documento descrive gli elementi di interessanti
per il tuning in Postgresql sia nell'ottimizzazione di
singoli statement SQL che dell'intero sistema.
Il documento e' stato inizialmente preparato sulla versione 9.4
di PostgreSQL su Linux ma e', mutatis mutandis, valido anche per le altre versioni
[NdA 2023-02-14: le impostazioni ed i parametri sono stati aggiornati alla
versione 15].
Vengono riportati elementi utili all'ottimizzazione SQL ed al tuning PostgreSQL:
Ottimizzazione delle prestazioni,
Tuning SQL,
Tuning PostgreSQL,
...
Statistiche prestazionali in PostgreSQL e' sicuramente il documento piu' utile per monitorare le prestazioni di PostgreSQL. Un documento introduttivo su PostgreSQL e' Introduzione a PostgreSQL, un documento piu' completo e' Qualcosa in piu' su PostgreSQL.
Le attivita' di ottimizzazione e tuning di sistemi database sono complesse e richiedono esperienze specifiche. Entrambe sono rivolte al miglioramento delle prestazioni. L'attivita' di ottimizzazione viene svolta in fase di progettazione e di sviluppo (eg. scrittura degli statement SQL). Con il tuning invece si cerca di trovare il compresso migliore tra tutti gli elementi configurabili del sistema.
E' possibile intervenire a diversi livelli:
Il linguaggio SQL e' apparentemente molto semplice, tuttavia per sfruttare appieno le possibilita' che offre e' necessario conoscerne le particolarita' e gli elementi specifici che ogni diversa implementazione presenta. PostgreSQL offre diverse estensioni del linguaggio SQL che comprendono nuove clausole, funzioni di utilita' ed un forte orientamento agli oggetti.
PostgreSQL utilizza un ottimizzatore cost-based.
Quando viene sottomesso uno statement SQL l'ottimizzatore determina
il query tree da utilizzare con un algoritmo genetico basato sulle statistiche.
L'algoritmo genetico e' utilizzato per ridurre il numero delle combinazioni
dei possibili percorsi di ricerca.
E' naturalmente molto importante che le statistiche su cui si basa l'ottimizzatore
siano aggiornate.
PostgreSQL esegue in automatico [NdE nelle release piu' recenti] le attivita' di analyze
(raccolta delle statistiche necessarie all'ottimizzatore)
e di vacuum (cancellazione dei blocchi non piu' necessari al MVCC).
Il livello di dettaglio dell'analyze e' determinato dal parametro default_statistics_target
(default: 100),
per tabelle con distribuzioni di dati particolari tale valore puo' essere modificiato
con ALTER TABLE SET STATISTICS.
L'ottimizzatore puo' essere parametrizzato con una serie di
impostazioni
nel file postgresql.conf.
Per verificare i tempi di esecuzione di uno statement SQL da psql basta utilizzare il comando \timing. Per ottenere dettagli su come l'ottimizzatore ha pianificato l'esecuzione di una query si utilizza la clausola EXPLAIN:
Vengono visualizzati gli algormitmi di accesso ai dati scelti dall'ottimizzatore
per eseguire la query. Oltre alle tabelle interessate sono riportati gli eventuali
indici: fondamentali per un accesso efficiente.
Con EXPLAIN ANALYZE la query viene anche eseguita e quindi riportati i
dettagli sui tempi effettivamente impegnati da ogni passo scelto dall'ottimizzatore.
E' possibile utilizzare l'EXPLAIN su tutti gli statement SQL e non solo sulle SELECT;
per non modificare dati utilizzando l'opzione ANALYZE e' possibile utilizzare una transazione:
BEGIN; EXPLAIN ANALYZE DML Statement ROLLBACK;
E' anche possibile modificare alcuni parametri dell'ottimizzatore nella sessione corrente ed analizzare le eventuali differenze sul query plan:
Vi sono parecchi parametri relativi al solo ottimizzatore che possono essere impostati [eg. nella versione 14 sono 47]. L'elenco si ottiene con select * from pg_settings where category like 'Query Tuning%';
Naturalmente un corretto disegno logico e disegno fisico della base dati sono necessari
perche' gli statement SQL possano essere eseguiti con buone prestazioni.
In particolare la presenza degli indici e' fondamentale per una corretta
esecuzione delle query (anche se vanno definiti i soli indici necessari
per non rallentare le esecuzioni degli statement di DML).
Il disegno di una base dati puo' essere molto differente a seconda
del tipo di utilizzo.
Con un OLTP il disegno e' normalizzato, se necessario overnormalizzato,
e sono presenti i soli indici necessari;
per un DWH il disegno e' fortemente denormalizzato,
sono tipicamente presenti tabelle/viste aggregate
e molteplici indici di ricerca.
Con un disegno opportuno Postgres e' in grando di ospitare entrambe
le tipologie di database anche se e' tecnicamente piu' adatto ad un uso OLTP.
PostgreSQL crea automaticamente gli indici per le primary key e quando
viene definito uno unique constraint.
Attenzione: gli indici per le foreign key debbono invece essere
creati esplicitamente.
In generale si mettono sempre tutte le PK e unique (e' automatico), tutte le FK (non e' automatico in Postgres),
gli indici composti delle condizioni utilizzate nelle query piu' frequenti partendo dalla colonna piu' selettiva.
Gli indici composti "valgono" anche come indici di grado inferiore se non sono presenti le colonne piu' a destra.
In caso di caricamento massivo dei dati di una relazione
e' conveniente non avere gli indici e crearli solo alla fine.
Un'ultima importante segnalazione: le applicazioni debbono effettuare le commit! Se non vengono effettuare le commit i lock non vengono rilasciati e, se questo avviene per un lungo periodo, i processi di autovacuum non possono liberare lo spazio. Determinare le sessioni che non hanno fatto commit e' molto semplice perche' sono in stato "Idle in Transaction" anziche' "Idle".
Maggiori indicazioni sull'ottimizzazione SQL si trovano in questa pagina.
Tutti gli statement SQL eseguiti su una base dati dovrebbero essere stati ottimizzati in fase di sviluppo... Ma questo non e' sempre possibile: vediamo quindi velocemente come determinare quali sono gli statement SQL che incidono maggiormente sulle prestazioni.
Sicuramente la prima cosa da controllare e' la vista la pg_stat_activity che riporta lo stato di tutte le connessioni alla base dati. pg_stat_activity riporta l'ultima query eseguita e l'indicazione se e' ancora attiva o meno. Controllando quali sono gli statement attivi nei momenti di picco di utilizzo della base dati e concentrando l'attenzione su questi si ottengono velocemente i primi risultati.
La seconda tecnica utilizzabile e' l'impostazione del parametro log_min_duration_statement di postgresql.conf che registra sul log gli statement di durata maggiore del parametro indicato (in millisecondi). Il parametro e' dinamico ed e' sufficiente un pg_ctl reload per modificarlo.
Le modalita' precedenti non sono in grado di rilevare statement di breve durata
ma eseguiti centinaia o migliaia di volte che possono sono quindi fondamentali
per le prestazioni nel loro complesso.
Per analizzare i tempi di ogni statement SQL viene utilizzata l'extension pg_stat_statements.
Ecco le prime 20 query ordinate per durata complessiva:
PostgreSQL mantiene in memoria una cache delle pagine (8K) piu' accedute. Maggiori sono gli accessi in memoria rispetto a quelli effettuati su disco migliori sono le prestazioni. L'Hit Ratio della cache dovrebbe essere stabilimente vicino al 100% e si misura con:
SELECT sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as hit_ratio FROM pg_statio_user_tables;
Per ragioni di efficienza e' molto importante che sopratutto gli indici vengano mantenuti in memoria. Con Postgres e' possibile controllare l'hit ratio di ogni singolo oggetto:
select blk.relname as relname,blk.heap_blks_read || ':' || blk.heap_blks_hit as heap_blk,
blk.idx_blks_read || ':' || blk.idx_blks_hit as idx_blk,
tpl.seq_scan || ':' || tpl.seq_tup_read as seq_tup,
tpl.idx_scan || ':' || tpl.idx_tup_fetch as idx_tup
from pg_statio_user_tables blk JOIN pg_stat_user_tables tpl using (relname);
Maggiori dettagli sono riportati nel documento Statistiche prestazionali in PostgreSQL ( Logging, pg_stat_statements, ...).
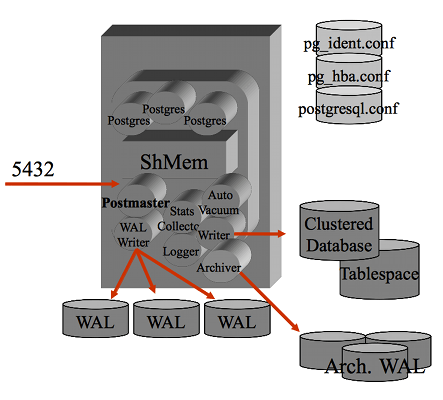
L'architettura Postgres... l'ho gia' descritta troppe volte! Riporto solo due figure che possono essere utili per meglio comprendere su cosa agisce il tuning:
Il tuning di PostgreSQL si esegue monitorando le prestazioni generali della base dati e modificando i parametri contenuti nel file postgresql.conf. I parametri a disposizione del DBA sono centinaia... naturalmente vedremo solo i piu' significativi.
Il tuning iniziale di PostgreSQL e' molto importante perche' la configurazione di default ha valori molto bassi per diversi parametri che incidono sulle prestazioni. Con questa scelta PostgreSQL funziona immediatamente anche su sistemi con pochissime risorse di memoria e di disco; pero' non e' ottimizzato su sistemi che hanno dimensioni maggiori come avviene su un tipico DB server.
La dimensione della buffer cache allocata e' impostata con
shared_buffers. Naturalmente il valore va impostato
a secondo della quantita' di RAM disponibile sul server:
tipicamente si inizia il 25% della RAM.
Quindi si monitorano l'Hit ratio e l'Hit count sul DB a regime.
Su un OLTP si cerca di essere vicini al 100% di Hit Ratio
sugli indici e superiori al 90% sulle tabelle.
E' possibile aumentare gli shared_buffers indicativamente fino al 50%
della memoria ma non di piu' perche' va lasciato spazio
alla buffer cache del sistema operativo (che Postgres utilizza)
e, sopratutto, alle aree di memoria delle sessioni connesse al DB.
Solo in qualche caso limitato e' possibile
usare una percentuale piu' alta (eg. molta memoria disponibile, poche sessioni)
ma spesso non risulta comunque vantaggioso.
Naturalmente il sistema ospite non deve entrare in paginazione/swapping
ed e' quindi importante monitorarne il comportamento (ed eventualmente
limitare l'impatto con vm.swappiness=1).
In ogni caso la prima verifica, in caso di Hit Ratio basso dopo la configurazione degli shared buffers,
e' sui sequential scan e quindi sul tuning delle query.
Un hit count basso e' indice che la cache puo' essere diminuita
senza impatti sulle prestazioni.
L'impostazione della effective_cache_size non
comporta alcuna allocazione ma permette all'ottimizzatore un
calcolo piu' preciso delle cache disponibili.
In pratica tiene conto che oltre agli shared_buffers
e' presente anche la cache del file system del sistema operativo.
Si imposta al 50% della RAM senza ulteriore tuning.
La work_mem e' la quantita' di RAM utilizzata dalle singole sessioni per il sort (ed altre funzioni interne). Il valore di default e' basso e si alza per evitare sort su disco o per effetturare hash join. La work_mem viene allocata solo quando serve ma e' difficile valutare quante richieste possano occorrere su tutte le connessioni presenti. Per questo si preferisce tenerla limitata come impostazione generale. Quello che e' certo e' che il numero di connessioni non puo' superare max_connections! L'impostazione di max_connections e' importante e su PostgreSQL vanno evitate troppe connessioni ai database se necessario utilizzando strumenti appositi. La maintenance_work_mem e' la quantita' di memoria riservata ai processi di ANALYZE e VACUUM; il default e' un po' basso: 64MB adatto solo se non vi sono molti DML, comunque si imposta sempre al di sotto del 5% della RAM.
La scrittura dei WAL utilizza i wal_buffers
come cache. Anche se possono avere una dimensione
inferiore non c'e' ragione ad non allocare almeno 16MB
poiche' l'impatto sulla memoria e' limitato
[NdA il parametro da impostare e' il numero di buffer ciascuno di 8K]
[NdE dalla 9.1 con l'impostazione di default -1 viene allocato il 3% del parametro
shared_buffers che generalmente e' un'impostazione piu' ragionevole dei 64KB
utilizzati in precedenza come default].
Il numero di checkpoint_segments impostato per default e' basso [NdA vale 3]
e viene generalmente aumentato per rendere piu' morbido l'utilizzo dell'I/O;
generalmente si imposta a 16 per salire fino a 256 (che corriponde a 4GB)
[NdE dalla 9.5 l'impostazione checkpoint_segments
e' stata sostituita con max_wal_size
che ha come un default ragionevole di 1GB].
Il checkpoint_timeout di default e' impostato a 5 minuti,
un valore generalmente ragionevole.
checkpoint_timeout puo' essere aumentato (eg. 30min)
con dischi SSD oppure ridotto (eg. 1min) su sistemi con molto I/O.
L'ideale e' che la maggioranza dei checkpoint siano temporizzati
[Nda si controlla con select checkpoints_timed, checkpoints_req from pg_stat_bgwriter].
Viene invece spesso variato per un tuning efficace il parametro
checkpoint_completion_target impostandolo
tra 0.5 (default) e 0.9 (massimo consigliabile).
Se i checkpoint avvengono con troppa frequenza tipicamente va aumentato il valore
di max_wal_size ma
e' importante monitorare anche l'I/O del sistema.
Un tuning piu' specifico per DB con un I/O significativo,
dopo avere verificato che il valore degli shared_buffers e' sufficiente,
puo' essere effettuato controllando la vista pg_stat_bgwriter.
Il numero di checkpoints_req deve essere vicino allo zero e nettamente inferiore a checkpoints_timed
se non e' cosi va aumentato il max_wal_size, eventualmente anche il min_wal_size,
e resi piu' frequenti i timed checkpoint diminuendo il checkpoint_timeout
[NdA teoricamente prima si aumenta solo il parametro max_wal_size
e solo se ancora necessario si abbassa il checkpoint_timeout].
Sempre sulla stessa vista va controllato il maxwritten_clean:
se e' alto vanno aumentato il parametro bgwriter_lru_maxpages.
Infine i buffers_clean debbono essere maggiori dei buffers_backend:
se non e' cosi' va aumentato il bgwriter_lru_multiplier e diminuito il bgwriter_delay.
Nelle versioni recenti di PostgreSQL
i thread di vacuum vengono eseguiti automaticamente...
pero' nel caso in cui il carico sia elevato o le tabelle
avessero lock potrebbero essere escluse con un notevole peggioramento
delle prestazioni ed una forte crescita dello spazio occupato.
Un veloce controllo e' possibile farlo sulla vista pg_stat_all_tables.
Mentre una verifica di dettaglio si effettua con la funzione
pgstattuple();
nel caso in cui le percentuali dead_tuple_percent OR free_percent
siano elevati e' opportuno eseguire un VACUUM ANALYZE sulle tabelle piu' importanti
o su tutto il DB
[NdA oppure VACUUM FULL ANALYZE che libera piu' spazio per il SO ma richiede un lock esclusivo].
In alternativa, ma generalmente si fanno entrambe le cose,
e' quella di rendere piu' frequenti ed aggressivi i thread di AUTOVACUUM
con autovacuum_vacuum_scale_factor = 0.05 (anche meno se le tabelle sono particolarmente grandi),
e con autovacuum_vacuum_cost_limit = 2000
[NdA per le versioni precedenti alla 12 e' anche utile autovacuum_vacuum_cost_delay = 2].
Maggiori dettagli sul tuning del VACUUM sono riportati in questa pagina.
Vacuuming rule: If it hurts, you’re not doing it often enough.
Quando il numero di transazioni e' elevato ed e' possibile ridurre i vincoli ACID con il rischio di qualche transazione nel remoto caso di caduta dell'istanza (eg. batch, restore) si possono utilizzare anche i parametri synchronous_commit e commit_delay [NdA anche se citato da alcuni e' invece sconsigliabile agire sul parametro fsync].
Se viene utilizzata la Streaming Replication o la replica logica vi sono altri importanti parametri di tuning per la replica da impostare. Tra i piu' utilizzati: wal_keep_size, max_slot_wal_keep_size, wal_keep_segments, max_standby_archive_delay, max_standby_streaming_delay, hot_standby_feedback, max_wal_senders, wal_sender_timeout, wal_receiver_timeout, wal_level, ...
Postgres ha molteplici parametri relativi al logging. In generale non hanno impatto sulle prestazioni a meno che non si esageri (eg. log_statement=all). Alcuni parametri di logging sono utili per estrarre le query piu lente (eg. log_min_duration_statement=5000) o per ottenere ulteriori informazioni (eg. auto_explain).
In qualche caso e' utile impostare alcuni timeout relativi alle sessioni: statement_timeout, idle_in_transaction_session_timeout, lock_timeout, idle_session_timeout [NdA PG14], ...
Se il numero di utenti e' limitato e' possibile incrementare i valori di
work_mem e hash_mem_multiplier che sono piuttosto bassi per default.
Con dischi SSD si abbassa la valutazione del costo
random_page_cost ma a livello di istanza
solo in casi molto particolari si modificano gli altri valori
dei parametri che incidono sull'ottimizzatore quali:
enable_seqscan, enable_bitmapscan,
...
E' piuttosto utile modificare tali parametri a livello di utente o di singolo statement
come pratica di Ottimizzazione SQL.
E' importante ricordare che in Postgres i parametri hanno context differenti:
ALTER SYSTEM SET shared_buffers='64GB'; -- Require restart
ALTER SYSTEM SET synchronous_commit=OFF; select pg_reload_conf();
ALTER DATABASE dwh SET synchronous_commit=OFF;
ALTER USER batch_user SET synchronous_commit=OFF;
SET synchronous_commit = 'off';
SET LOCAL synchronous_commit = 'off';
E' molto importante che il tuning della base dati venga eseguito
tenendo conto delle caratteristiche e dell'utilizzo del sistema ospite.
Una stima della memoria fisica massima occupata da un'istanza Postgres e' data dalla formula:
Max RAM = shared_buffers + (temp_buffers + work_mem) * max_connections
La formula non riene conto delle altre importanti aree che vengono allocate (eg. wal_buffers),
che non tutte le sessioni sono sempre connesse, che la work_mem non e' necessariamente usata
tutta, che la stessa sessione puo' utilizzare piu' aree di work_mem e quindi richiedere piu' memoria, ...
pero' e' gia' molto indicativa.
Riassumendo quanto riportato in questo documento,
una configurazione iniziale
per un sistema dedicato a PostgreSQL con 8GB di RAM
da cui partire per effettuare un tuning specifico,
e' la seguente:
listen_addresses = '*' max_connections = 100 shared_buffers = 2048MB effective_cache_size = 4096MB work_mem = 2MB maintainance_work_mem = 20MB wal_buffers = 64MB max_wal_size = 2GB checkpoint_completion_target = 0.9 log_min_duration_statement=5000 log_statement=ddl shared_preload_libraries = 'pg_stat_statements'
Infine le estensioni piu' significative per il tuning, in ordine di importanza a mio modesto parere, sono:
Auguri!
Titolo: Tuning PostgreSQL
Livello: Esperto
Data:
14 Febbraio 2015 ❤️
Versione: 1.0.7 - 14 Febbraio 2023
Autore: mail [AT] meo.bogliolo.name